
2019 회고록을 작성하면서 올해 한가지 마음 먹은것이 있었다. 바로 생산성에 대한 부분이다.
사실 아직 생산성이 무엇을 말하는지는 정확하게 감이 오지는 않지만, 예전에 같이 일했던 그분1의 말에 의하면 꾸준함과 예측가능함 인 것 같다. 본인의 일하는 패턴과 평소 생산량을 어느정도 측정할 수 있다면 일정을 예측하는 것이 더 쉬워질 것이고, 일정을 예측했다면 적절한 업무량 분배로 overdrive를 막아준다는 이야기다.
그분1의 이야기와는 별개로, 개인적으로 생각하는 생산성이란 효율인것 같다. 다시말해, 한정된 시간에 집중한 정도를 심리적 지표가 아닌 객관적 지표로 나타낸 것을 말한다. 이렇게 탄생한 숫자는 거짓말을 하지 않기 때문에, 자기객관화 혹은 냉정한 자기평가에 도움을 줄 수 있겠다는 생각을 하게 되었다.
그렇게하여, 자매품인 rescuetime report bot과 함께 간단하게 Github report bot을 만들게 되었다.
1. Github report bot?
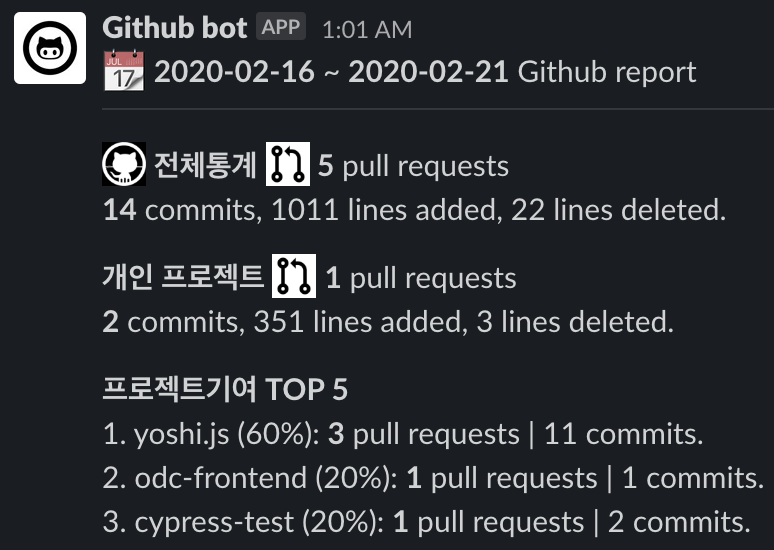
1주일 간(일요일 ~ 금요일)의 Github 통계를 간단하게 보여준다. 메시지는 매주 토요일 오전 1시에 slack으로 받고있다. 회사의 프로젝트들도 Github로 관리하고 있기 때문에, 개인 프로젝트와 나누어 통계를 낼 필요도 있었다. 아직까지는 부담스럽지 않으며(이 부분이 중요한 것 같다), 일주일을 돌아보는 용도로 잘 활용하고 있다.
2. 프로젝트 구성
-
언어
늘 그렇듯
Typescript를 사용하였다. 3.7에서 추가된 optional chain과 nullish coalescing을 사용해 보고 싶기도 했고(이때 아직 회사의 프로젝트는 3.5 버전이었다), 빠르게 무언가를 만들어야하는 상황이었기 때문에 제일 익숙한 것을 선택하였다. -
주요 라이브러리
axios: Github api와의 통신을 위해 선택했다.ramda: Data를 가공하기 위해 선택했다. 개인적으로 lodash보다 더 선호하는 라이브러리이다. 기본적으로 모든 함수가 currying되어있고, 지원하는 함수의 숫자가 상당하기 때문에 즐겨사용한다. 나중에 lodash와 비교하는 글을 써볼까 생각중이다.dayjs: moment보다 가벼운, 경량의 시간 관련 라이브러리이다. 동료인 제프리가 추천해준 덕분에 아주 잘 사용하고 있다.
-
CI
Github Actions: 다른 CI에 의존하지 않고 repository에서 관리할 수 있기때문에 선택했다. 개인 프로젝트를 진행할때는 항상 선택하고 있다.
-
Cloud platform
GCP functions: 항상 AWS만 써왔었는데, 우연한 기회로 GCP credit을 얻게되어 사용하게 되었다. 사용해보니 생각보다 번잡하지도 않고, cli도 충분히 잘 지원하고 있다는 생각이 들었다. 앞으로 개인 프로젝트를 진행할때 선택하고싶지만, 현재 다니고 있는 회사가 AWS비용을 전부 지원해주고 있기 때문에 고민이 되는 부분이다.
3. Github api와 연동하기
프로젝트 directory를 만들고 git과 npm을 init한 다음, 기반이 될 라이브러리들을 설치해 주었다. 이 외에 eslint, prettier, jest등을 설치해 주었다(설치와 설정에 대한 좋은 글들은 많이 있어 여기서는 생략하고자 한다).
$ npm install --save axios dayjs ramda typescript1. Github api v4 사용하기
Github api v4 부터 graphql을 지원한다. 처음에는 기존의 rest api를 사용하였는데, 필요없는 정보들이 너무나 많이 포함되어 있어 고민을 하고 있었다(궁금하면 직접 보자). 이때 그분2가 나타나 Github api가 graphql을 지원한다는 사실을 알려주었고, 덕분에 굉장히 쉽고 직관적으로 api를 연동하는 부분을 구성할 수 있었다.
특히 GraphiQL을 따로 설치할 수 있어, 마치 postman처럼 graphql query를 쉽게 테스트해볼 수 있었다. 본인의 경우에는 query를 테스트하며 response data의 구조를 interface로 만들었다.
interface Author {
login: string
}
interface Commit {
totalCount: number
}
interface Repository {
owner: Author
name: string
}
interface ResultNode {
__typename: 'PullRequest' | 'Issue'
createdAt: string
closed: boolean
title: string
additions: number
deletions: number
state: 'OPEN' | 'MERGED' | 'CLOSED'
author: Author
commits: Commit
repository: Repository
}
interface GithubResponse {
data: {
search: {
issueCount: number
nodes: ResultNode[]
}
}
}
type PullrequestNode = Omit<ResultNode, '__typename'> & {
__typename: 'PullRequest'
}2. Api 연동하기
Api를 호출하기 위해서 특정 권한을 갖고있는 personal access token을 먼저 만들어야 한다. Personal access token은 user profile -> Developer settings -> Personal access token에서 생성할 수 있다. Token을 만들었다면, 완성된 query를 통해 data를 불러오는 로직을 작성한다.
const query = (from: string, to: string) => `
query {
search(query: "author:stardustrain created:${from}..${to}", type: ISSUE, first:100) {
issueCount
nodes {
__typename
... on PullRequest {
createdAt
closed
title
additions
deletions
state
author {
login
}
commits {
totalCount
}
repository {
name
owner {
login
}
}
}
}
}
}
`
const instance = axios.create({
baseURL: 'https://api.github.com/graphql',
headers: {
Authorization: `bearer ${process.env.GITHUB_API_KEY}`, // Personal access token
},
})
const res = await instance.post<GithubResponse>('', {
query: query(from, to),
})성공적으로 요청하였다면 대략 다음과 같은 모양의 data를 볼 수 있다. 그렇다면 이제 data를 적당히 만지면서, 보고싶은 부분을 잘 추출하면 된다.
{
"data": {
"search": {
"issueCount": 1,
"nodes": [
{
"__typename": "PullRequest",
"createdAt": "2020-01-06T09:38:11Z",
"closed": true,
"title": "PULL REQUEST TITLE",
"additions": 14,
"deletions": 5,
"state": "MERGED",
"author": {
"login": "stardustrain"
},
"commits": {
"totalCount": 2
},
"repository": {
"name": "REPOSITORY NAME",
"owner": {
"login": "stardustrain"
}
}
}
]
}
}
}3. 알고싶은 수치 꺼내기
본인이 알고싶었던 수치는 다음과 같았다.
- Pull request count
- Commit count
- Line addtion, line deletion
위의 항목을 다음의 분류에 따라 각각 계산하였다.
- 전체 프로젝트
- 개인 프로젝트
- 기여한 프로젝트 Top 5
이 로직을 만들때 정교한 알고리즘보다는 누가 보더라도 역할을 충분히 알 수 있는 여러개의 함수를 만들어 잘 조합하는 일이 더 중요한 포인트라고 생각했다. 사실 depth가 깊어 귀찮을 뿐 크게 어렵지 않은 작업이었다.
예를들어 Pull request들을 repository 이름으로 grouping -> 필요한 정보를 추가 -> sorting하는 부분을 다음과 같이 구현하였다.
먼저, 각각의 계산을 도와줄 helper함수들을 먼저 작성했다.
export const getLineCount = (prNodes: PullrequestNode[]) =>
prNodes.reduce(
(acc, prNode) => ({
additions: acc.additions + (prNode.additions ?? 0),
deletions: acc.deletions + (prNode.deletions ?? 0),
}),
{
additions: 0,
deletions: 0,
}
)
export const getCommitsCount = (prNodes: PullrequestNode[]) =>
prNodes.reduce((acc, prNode) => acc + (prNode?.commits?.totalCount ?? 0), 0)
export const generatePRInformation = (prNodes: PullrequestNode[]) => ({
lines: getLineCount(prNodes),
commits: getCommitsCount(prNodes),
totalPRCount: prNodes.length,
})그리고 그 함수들만 적절히 사용하면 간단하게 끝난다. 함수의 조합(composition)을 적극적으로 사용해 보고싶었는데, 생각보다 필요한 부분이 많지 않았다.
type GroupedProject = ReturnType<typeof getProjectsGroupbyRepository>
export const getProjectsGroupbyRepository = (prNodes: PullrequestNode[]) =>
groupBy(node => node.repository.name, prNodes)
export const getContributionByRepository = (
projects: GroupedProject,
criteria: 'commits' | 'totalPRCount' = 'totalPRCount'
) =>
pipe(
keys,
map<string, [string, PRInformation]>(key => [key, generatePRInformation(projects[key])]),
sortBy(v => negate(prop(criteria, v[PR_INFORMATION_INDEX])))
)(projects)
const result = getContributionByRepository(getProjectsGroupbyRepository(prNodes))4. Slack webhook 연동하기
1. Slack에서 webhook 설정하기
처음에는 단순히 workspace의 webhook을 설정하려고 하였으나 공식 사이트의 권고가 있어 slack app으로 만들게 되었다.

- 먼저 slack api에서
Create New App을 누른다. - App의 이름과 slack workspace를 설정한다.
- App이 잘 만들어졌으면, 왼쪽 sidebar에서
Incoming Webhooks를 선택한다. Add New Webhook to Workspace를 눌러 메시지를 받을 채널을 선택한 후Allow를 누른다.- Webhook URL위에 보이는 sample code를 terminal에서 실행하여 메시지를 제대로 받는지 확인한다.
curl -X POST -H 'Content-type: application/json' --data '{"text":"Hello, World!"}' WEBHOOK_URL2. Message 만들기
미리 말하자면, 이 부분에서 시간이 제일 오래 걸렸다. 굉장한 노가다 작업이고, 사람의 욕심은 끝이없기때문에 일단 layout부분은 자기자신과 타협을 해야했다. Slack의 block layout 문서를 참고하면 된다.
본인의 경우, 문자열을 만들어내는 generator 역할을 하는 함수를 만들고, block layout을 return하는 함수에 사용하는 방식으로 구현하였다.
export const generateTotalInfoMessage = ({
lines,
commits,
totalPRCount
}: PRInformation) => {
const emogi = getTotalPRCountEmogi(totalPRCount);
return `:github: *전체통계* :merge: *${totalPRCount}* pull requests ${emogi}\n *${commits}* commits, ${lines.additions} lines added, ${lines.deletions} lines deleted.`;
}
export const weeklyMessageBlock = ({
total,
}: MessageParams) => ({
text: 'Github report of a last week!',
blocks: [
{
type: 'section',
text: {
type: 'mrkdwn',
text: total
}
}
]
})
const message = weeklyMessageBlock({ total: generateTotalInfoMessage({ ... }) })Block layout이 변경될 때 마다 slack으로 message를 보내는것이 번거롭다면, block kit builder를 사용하면 된다. Builder를 사용해 자잘한 부분을 수정하고, 어느정도 큰 틀이 완성되었을때 slack으로 message를 보내 확인하는 방법으로 시간을 절약할 수 있었다.
3. Message 보내기
먼저, node.js에서 slack webhook을 보내는데 필요한 라이브러리를 설치하였다.
$ npm install --save @slack/webhook사용하는 방법은 굉장히 간단하다. Webhook 관리 페이지에서 확인가능한 webhook url과 메시지 object만 있으면 된다.
import { IncomingWebhook } from '@slack/webhook'
const message = weeklyMessageBlock({ total: generateTotalInfoMessage({ ... }) })
const webhook = new IncomingWebhook(WEBHOOK_URL)
webhook.send(message)node를 통해 실행했을때, message를 slack으로 받을 수 있다면 이제 한 고비만 넘으면 된다.
5. 배포하기
1. GCP 설정하기
-
프로젝트 만들기
GCP에 가입하는 것은 그리 어렵지 않다. 가입을 하고 난 뒤, navigation bar에 있는
프로젝트 선택을 클릭한다.
Modal창이 뜨면
새 프로젝트를 클릭하여 프로젝트를 생성한다.
-
IAM 설정하기
프로젝트를 만들었다면, navigation bar에서 햄버거 메뉴를 클릭한다. Sidebar가 나오면,
IAM & Admin을 클릭한다. IAM을 관리하는 화면이 나타면, 왼쪽 sidebar에 있는Service Accounts메뉴에 들어간다. 위쪽의서비스 계정 만들기를 클릭하고 나중에 구분할 수 있는 이름을 짓는다.
만들기를 누르고,역할을 눌러 활성화된 dropdown menu에서 프로젝트의편집자역할을 부여한다. 다음으로 화면이 넘어가면,키 만들기를 눌러JSON형태로 다운로드 받는다. 키 파일은 GCP의 자원에 접근할 수 있는 권한을 부여하는 역할을하며, 실수로 삭제할 경우 key file을 다시 만들어야하니 주의하여 다뤄야 한다.
여담이지만, 예전에 실수로 aws credential key를 github에 push하는 사람들이 종종 있었다. 그리고 자신도 모르는 사이에 최고사양의 ec2가 비트코인을 채굴하여 어마어마한 사용료가 나오곤 했다. 그렇기 때문에, 이 key파일을 프로젝트 directory에 넣는 것을 추천하지 않는다. 자신도 모르게 실수가 발생할 수 있기 때문이다.
-
키 확인하기
다운로드 받은 키를 열어보면 다음과 같은 정보를 포함하고 있다.
{ "type": "service_account", "project_id": "PROJECT_ID", "private_key_id": "PRIVATE_KEY_ID", "private_key": "PRIVATE_KEY", "client_email": "CLIENT_EMAIL", "client_id": "CLIENT_ID", "auth_uri": "AUTH_URI", "token_uri": "TOKEN_URI", "auth_provider_x509_cert_url": "AUTH_PROVIDER_CERT_URL", "client_x509_cert_url": "CLIENT_CERT_URL" } -
Cloud Scheduler 설정하기
Github report는 매주 토요일 오전 1시에만 메시지를 받으려는 목적이 있었다. 결국 배포한 함수를 매주 토요일 오전1시에 실행시켜야 한다는 것인데, 이는 GCP의 Cloud Scheduler가 역할을 잘 해줄 수 있다. GCP의 Cloud Scheduler메뉴에 들어가서,
작업 만들기를 클릭한다. 스케쥴의 이름을 정하고, 시간대를한국 표준시(KST)로 설정한다.중요한 것은 빈도와 대상인데, 빈도는 전형적인 unix-cron의 형식을 따른다. 이곳에서 crontab 시간을 설정했다. 매주 토요일 오전 1시는
0 1 * * 6로 표현할 수 있다.대상은
게시/구독을 선택한다. 그러면주제를 적는곳이 나오는데, 여기에다가 구분 가능한 문자열을 써 넣는다. 나중에 함수를 trigger할 때 필요한 문자열이니 아무렇게나 써넣지 않는 것을 추천한다.
2. gcloud 설치
gcloud는 GCP의 리소스에 접근하기 위한 cli 명령어들을 제공하는 도구이다. Google Cloud SDK 문서를 참고하여 gcloud cli를 설치한다. 설치가 끝난후, 다음과 같이 확인해본다.
$ gcloud --version
Google Cloud SDK 274.0.1
bq 2.0.51
core 2019.12.27
gsutil 4.463. 배포준비
-
코드 정리
당연한 이야기지만, 코드를 정리해야 한다. Functions를 작성할때는
package.json의main필드와 실제로 실행할 함수를 exports하는 경로를 맞춰야 한다. 일반적으로index.(t|j)s에서 함수를 exports하는 형식으로 구조화 하면 혼란을 막을 수 있을 것 같다.const helloWorld = () => { // business logic } // Run blow functions export const hello = () => { helloWorld() } // javascript exports.hello = function () { helloWorld() }설명이 조금 어려운 느낌인데, GCP의 문서에는 아래와 같이 적혀있다.
Node.js 런타임의 경우 함수의 소스 코드는 Cloud Functions가 require() 호출로 로드하는 Node.js 모듈에서 내보내야 합니다. 로드할 모듈을 결정하기 위해 Cloud Functions는 package.json 파일의 main 필드를 사용합니다. main 필드가 지정되지 않은 경우 Cloud Functions는 index.js에서 코드를 로드합니다.
자세한 것은 이곳을 참고한다.
-
.gcloudignore 설정
GCP functions는 먼저 파일을 압축하여 storage butcket으로 업로드 한다.
.gcloudignore는 업로드 할 때 제외하거나 포함할 파일을 지정하는 역할을 한다..gitignore와 비슷한 역할을 하는 파일로, 프로젝트 root에.gcloudignore파일을 만든다. 그리고 다음과 같이 작성한다..git .gitignore .github node_modules src/ README.md tsconfig.json jest.config.js !/dist.gitignore에 포함된 경로와 node_modules, src/ 등 함수의 동작에 필요없는 것들을 제외했다. 본인의 경우 typescript를 사용하고 있었기 때문에, tsconfig.json에서
outDir로 지정된dist/아래에 위치한 파일들만 업로드하면 되었다. 그래서!/dist를 추가해, 이 경로 하위의 파일들은 업로드가 되도록 지정했다.쉽게말해, 배포에 정말 필요한 파일들만 지정하면 된다.
-
package.json 설정
위에서도 설명하였지만, 최종적으로 실행할 코드는
dist/의 하위에 위치하기 때문에,main필드를 지정해야 한다.// package.json { ... "main": "./dist/index.js", ... } -
사전 배포 테스트
본격적으로 CI 배포를 준비하기 전에, local 환경에서 배포가 잘 되는지 테스트해볼 필요가 있다. (당연할수도 있겠지만) 본인의 경우 local에서 성공한 배포 명령어를 CI에 거의 그대로 이식하는 편이다. Local에서는 편하게 테스트하기 위해, 아까만든 key파일이 아니라 web으로 login하여 gcloud cli를 사용하였다.
$ gcloud auth login // 로그인 후 $ gcloud init로그인 -> cli에서 사용할 계정을 선택 -> 프로젝트를 선택하면 가볍게 끝난다. 이후 다음 명령어를 통해 활성화된 계정의 정보를 확인한다.
$ gcloud info ... Account: LOGIN_ACCOUNT Project: PROJECT_ID Current Properties: [core] project: PROJECT_ID account: LOGIN_ACCOUNT정상적으로 계정이 activate되었다면, 다음 명령어를 실행한다.
gcloud functions deploy FUNCTION_NAME --project=PROJECT_ID --runtime nodejs10 --update-env-vars GITHUB_API_KEY=YOUR_GITHUB_API_KEY,HOOK_URL=YOUR_HOOK_URL배포가 정상적으로 완료되었다면 functions dashboard에서 확인할 수 있다.
4. CI 설정
Github Actions로 배포를 자동화하기전에, 몇몇 민감한 정보나 환경변수를 CI service에 미리 설정할 필요가 있다. 예를들어, 배포에 필요한 권한이 들어있는 key 파일들이나, project id 등이 그렇다(이는 다른 CI service도 마찬가지이다).
프로젝트의 github page > settings > Secrets에 들어가면, 이렇게 Github Actions가 실행되는데 필요한 변수들을 key-value 형태로 저장할 수 있다. 일단 배포에 필요한 환경변수와 project id를 저장한다. Add a new secret을 클릭하고, 각각 GITHUBAPIKEY, HOOKURL, *PROJECTID*의 key에 해당하는 값을 넣고 Add secret을 누른다.

이제 배포에 필요한 key 파일 역시 환경변수로 지정해야한다. Github Actions의 배포머신에서는 아까와 같이 web으로 login할 수 없기 때문에, key 파일을 통해서만 GCP의 리소스에 접근할 수 있다. Service account를 생성하고 다운받은 키파일의 내용을 base64로 encoding하여 secret에 저장하면 된다.
$ cat YOUR_KEY_FILE | base64위의 명령을 입력하면 terminal에 encoding된 string이 나오고, 이를 전체 복사하여 secret에 저장해 주면 된다. 본인의 경우 GCPSAKEY라고 저장했다.
5. 배포
Github Actions의 기능은 방대하기 때문에 자세한 것은 Github Actions Documentation을 참고하면 좋을 것 같다. 여기서는 필요한 부분만 적으려고 한다.
먼저 프로젝트 directory의 root에 .github/workflows directory를 만들었다.
<project-directory>$ mkdir -p .github/workflows성공적으로 만들어졌다면, .github/workflows의 하위에 main.yml 파일을 만들어 준다(확장자만 맞춰준다면 파일이름은 상관 없는 것 같다). 여기에 배포와 관련한 CI command를 작성했다. 자세한 pipeline은 이곳 에서 확인 할 수 있으며, 여기서는 배포와 관련한 command만 쓰려고 한다.
on:
push:
branches:
- master우선, master branch에 commit되면 배포 pipeline이 동작하게 했다. 배포과정은 build 후 artifact를 만들어 업로드하고, 그것을 다음 step에서 다운로드 받아 functions에 배포하게끔 설정하였다(지금와서 생각해보면 하나의 step에서 다 끝내도 괜찮았을 것 같다).
build:
name: Build
needs: test
runs-on: ubuntu-latest
steps:
- name: Checkout master
uses: actions/checkout@master
- name: Install dependencies
run: npm install
- name: Build
run: npm run build
- name: Archive build artifact
uses: actions/upload-artifact@master
with:
name: dist
path: ./dist이 step이 오류없이 동작하면 dist/하위의 파일들이 dist라는 이름으로 artifact가 만들어져 actions에 업로드 된다. 업로드 된 파일은 정상적으로 동작이 끝난 pipeline에서 확인해 볼 수 있다.

이 다음 step에서는 dist artifact를 다운로드 받아 그대로 functions에 배포하도록 작성한다.
deploy:
name: Deploy
needs: [test, build]
runs-on: ubuntu-latest
steps:
- name: Checkout master
uses: actions/checkout@master
- name: Download artifact
uses: actions/download-artifact@master
with:
name: dist
path: ./dist
- name: Activate GCP service account
uses: GoogleCloudPlatform/github-actions/setup-gcloud@master
with:
version: '274.0.1'
service_account_key: ${{ secrets.GCP_SA_KEY }}
- name: Deploy
run: |
gcloud functions deploy YOUR_FUNCTION_NAME --runtime nodejs10 --trigger-topic TOPIC_NAME --project=${{ secrets.PROJECT_ID }} --region asia-northeast1 --update-env-vars GITHUB_API_KEY=${{ secrets.GITHUB_API_KEY }},HOOK_URL=${{ secrets.HOOK_URL }}deploy step을 잘 살펴보면, 일단 build step에서 만들어진 artifact를 다운로드 받는다. 그 후 GoogleCloudPlatform이라는 다른 사람이 작성한 action pipeline을 통해 빌드머신에 gcloud를 설치하지 않고도 gcloud cli를 통해 배포하는 단순한 과정으로 되어있다.
YOUR_FUNCTION_NAME의 자리에는 main filed로 지정된(지정하지 않았다면 index.js)에서 실제로 실행할 함수의 이름을 적어준다.
--trigger-topic option뒤에는 아까 설정한 cloud scheduler의 주제를 적어 넣는다. 이렇게하면, 아까 만들어둔 scheduler가 crontab으로 설정한 시간이 되면 해당 주제로 trigging하여, 같은 주제를 구독하고 있던 이 functions가 실행된다.
6. Conclusion
가벼운 마음으로 시작해 즐겁게 끝냈던 프로젝트였다. 난이도는 도전하기에 적당했고, 완성한 뒤에도 유용하게 쓰고 있어서 꽤 괜찮았던 프로젝트로 기억에 남는다. 게다가 지금 회사에서 그분2가 지시한 비슷한 개발 프로젝트도 무리없이 진행하고 있다.
제일 좋았던 것은 이 프로젝트를 진행하면서 다양한 부분을 조금씩 해볼 수 있었다는 것이다. 기본적인 기능구현은 빼놓고서라도, CI 설정이나 GCP 설정 등 평소 회사에서는 좀처럼 해볼 수 없는 작업들을 한 것이 가장 큰 소득이었다고 생각한다.
Q2 ~ Q3 사이에는 이를 기반으로 더 커진 프로젝트를 구상하고 있는데, 만약에 이번처럼 즐겁게 잘 끝낼 수 있다면 다시 이런 글을 써볼 생각이다.