
1. TCP 커넥션
보통의 경우, 클라이언트와 서버는 다음의 순서대로 통신을 하게 된다.

- 브라우저에서 URL과 포트를 입력
- DNS를 통해 서버의 ip주소를 획득
- 브라우저와 서버간의 커넥션 생성
- 브라우저가 request message를 보냄
- 서버가 request에 대한 response message를 보냄
- 브라우저와 서버간의 커넥션이 끊김
HTTP 통신은 TPC/IP를 통해 이루어 진다. 일단 TCP/IP 커넥션이 맺어지면 클리아언트와 서버간에 메시지를 주고받을 수 있게 된다.
1. TCP란?
신뢰기반의 전송 프로토콜로, 주고받는 메시지간의 무결성과 순서를 보장하여 메시지를 안전하게 전달할 수 있다. TCP 스트림은 segment로 나누어져 IP 패킷을 통해 전송된다.
HTTP와 TCP간의 관계를 알아보려면, 먼저 TCP/IP layer에 대해 알고 있으면 쉽게 이해할 수 있다.
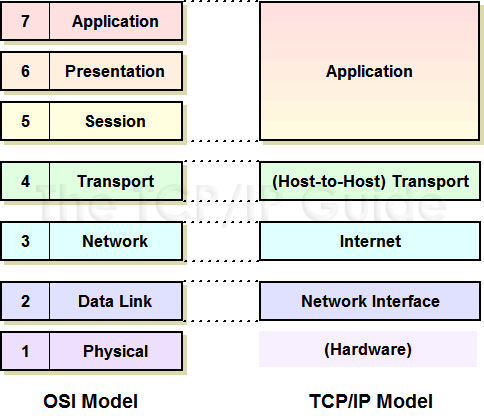
HTTP message를 전송하고자 할 경우 TCP라는 프로토콜을 통해 전송하려는 message가 segment화 되고, 이 segment들은 IP 패킷에 담겨 전송된다.
Message를 수신하는 쪽에서는 패킷에 담겨온 메시지를 차례대로 unpacking(적당한 용어는 아니지만 이렇게 이해하면 좋을 것 같다)하는 과정을 거쳐 HTTP message를 알아볼 수 있게 된다.
application layer에 해당하는 HTTP는 하위계층의 프로토콜을 이용해 통신할 수 있게되며 이는 프로토콜 스택이라 불린다.
2. TCP의 커넥션 유지
컴퓨터는 항상 여러개의 커넥션을 가지고 있다. TPC는 포트를 이용하여 여러개의 커넥션을 유지할 수 있다.
TCP 커넥션은 네 가지의 값을 가지고 커넥션을 식별한다.
<sender ip, sender port, receiver ip, receiver port>이 값들은 두 가지 특징을 지닌다.
- TCP는 위의 네 가지 값으로 커넥션을 식별하고 생성한다.
- 위의 구성요소들은 서로 다른 커넥션 끼리 중첩할 수 없다.
3. Socket?
소켓이란 네트워크를 이용한 기기간 통신의 종착점을 의미한다 참고. 조금 더 풀어서 설명하자면, 클라이언트와 서버가 커넥션을 맺었을 때 클라이언트와 서버가 데이터를 읽고 쓸수 있게 해주는 일종의 입구 역할을 하게 된다. 소켓은 결국 TCP 커넥션에 대한 interface라고 생각하면 좋을 것 같다.
소켓 API를 통해 브라우저와 서버간의 통신방법을 살펴보자면 다음과 같다.

2. TCP의 성능에 대한 고려
위의 osi 7 layer에 대해서 살펴본 것 처럼, HTTP는 결국 하위계층들의 도움을 받아야 message를 주고받을 수 있게되고 결국 TCP의 성능에 크게 영향을 받게 된다. 따라서 HTTP의 성능을 고려하기 전에 TCP의 성능에 대해 고려하는 것이 좋다.
1. HTTP 트랜잭션의 지연
- 요청에 대해서 서버가 처리하는 시간은 짧지만, 연결, 요청, 응답은 상대적으로 늦게 처리된다. 이는 서버와 클라이언트간의 거리, 네트워크 장비의 부하, 인터넷 혼잡도 등의 영향을 받기 때문에 일어난다.
-
HTTP 트랜잭션 지연의 원인은 다음과 같다.
- DNS 요청으로 인한 지연
- 클라이언트-서버 사이의 커넥션 설정으로 인한 지연
- 커넥션이 맺어진 후 요청 전달시 지연
- 요청 처리 후 응답을 보내는 과정에서의 지연
이러한 지연들은 위에서도 설명하였지만 하드웨어의 성능, 서버의 전송속도, message의 크기, 서버와 클라이언트간의 거리 등에 따라 변한다.
2. 3 way handshake 지연
TCP는 커넥션을 맺기 전에 연결 성립을 위한 3단계의 과정을 거친다.
- 먼저 클라이언트가 서버측에 SYN 패킷을 보낸다.
- 서버는 SYN 패킷을 받고 클라이언트 측의 요청을 수락하는 의미로 ACK 패킷과 SYN 패킷을 보낸다.
- 클라이언트는 서버의 SYN 패킷을 받고 요청을 수락하는 의미로 ACK 패킷을 보낸다.
위와 같은 과정을 3 way hanshake라고 한다. 이 과정에서도 지연이 발생하는데, 원인은 다음과 같다.
- HTTP 커넥션이 아주 크지 않는 이상, SYN / SYN-ACK 패킷을 주고 받는 과정에서 지연
- ACK 패킷이 생각보다 큰 용량을 차지
이는 이미 존재하는 커넥션을 재사용하는 것으로 해결이 가능하다.
3. 확인응답 지연
인터넷 자체는 완벽한 패킷 전송을 지원하지 않는다. 한 예로 라우터의 경우 과부하 상태일 시 패킷을 마음대로 파기할 수도 있다. 그렇기 때문에 각 TCP segment는 순번과 데이터 무결성을 보장하는 checksum 데이터를 갖는다.
각 segment의 수신자는 segment를 정상적으로 받으면 작은 크기의 확인응답(ACK 혹은 NACK) 패킷을 송신자에게 반환한다. 만약 송신자가 특정 시간 안에 확인응답 패킷을 받지 못하면 오류로 간주하여 데이터를 재전송하게 된다.
확인응답 패킷의 경우 크기가 작기 때문에 (1비트 짜리 flag value일 수도 있다) 보통 같은 방향으로 송출되는 패킷에 편승시킨다. TCP는 확인응답 지연 알고리즘을 구현한다. 송출되는 확인응답을 0.1 ~ 0.2초간 버퍼에 저장해 두었다가 편승시키기 위한 패킷을 찾게되는 것이다. 만약 일정 시간 안에 패킷을 찾지 못하면, 별도의 패킷을 만들어 전송한다.
HTTP의 경우, request와 response라는 두 가지 방식으로만 통신하기 때문에 생각보다 편승할 기회가 감소하여 결과적으로 이 알고리즘으로 인한 지연이 자주 발생한다.
4. TCP slow start
TCP 커넥션은 시간이 지날수록 자체적으로 성능이 튜닝되는 특성이 있다. 이는 처음에는 전송 속도를 제한하다가 데이터가 성공적으로 전송됨에 따라서 점진적으로 속도를 높이는 TCP의 특징을 말한다.
TCP slow start라는 커넥션이 맺어진지 얼마 되지 않았을 경우, 한 번에 전송시킬 수 있는 패킷의 수를 제한하는 것을 의미한다. 패킷이 성공적으로 전달된 시점에서 추가로 패킷을 더 전송할 수 있는 권한을 얻는데, 이를 opening the congetion window라고 한다. 이는 급작스러운 부하와 혼잡을 방지하는데 사용된다.
하지만 이는 역시 얼마간 통신 속도를 느리게하는데 영향을 준다. 특히 request에 대한 response를 처리하면 서로 커넥션을 끊어버리는 HTTP의 특성상 더욱 그러하다. 그렇기 때문에 이 문제 역시 이미 존재하는 커넥션을 재사용 하는 것으로 해결된다.
5. Nagle 알고리즘과 TCP_NODELAY
Nagle 알고리즘(RFC896)이란 네트워크 효율을 위해 패킷을 버퍼에 모았다가 한 번에 전송하는 알고리즘을 뜻한다. Nagle 알고리즘은 가능하면 조금씩 여러번 보내지 말고 한 번에 많이 보내라는 원칙에 기반한다. 이 알고리즘은 다음과 같은 특징이 있다.
- 다른 모든 패킷이 확인응답을 받은 경우 segment의 최대 크기가 작더라도 패킷을 전송할 수 있다.
- 만약 다른 패킷들이 전송중일 경우 데이터를 출력버퍼에 저장했다가 ①확인 응답을 받거나 ②segment 최대 크기까지 커지면 출력버퍼의 내용을 전송한다.
만약 A가 B에게 ‘Nagle’이라는 글자를 보낸다고 했을때 위에서 설명한 일반적인 네트워크 통신방법을 사용하면 다음과 같이 전송될 것이다.
- A는 ‘N’이라는 데이터를 패킷으로 만들어 전송한다.
- ACK를 기다리지 않고 순차적으로 ‘a’, ‘g’, ‘l’, ‘e’를 각각 패킷으로 만들어 보낸다.
- ACK를 기다렸다가 일정 시간이 지난 후 받지 못하면 다시 재전송한다.
하지만 Nagle 알고리즘을 사용하면 다음과 같이 전송된다.
- A는 ‘N’이라는 데이터를 패킷으로 만들어 전송한다.
- ACK가 오기 전 까지 ‘agle’을 출력버퍼에 저장한다.
- ACK를 받으면 ‘agle’을 한 번에 전송한다.
그렇기 때문에 크기가 작은 message는 추가적인 데이터를 기다려야 하며, 확인응답 지연과 함께 쓰일 경우 성능이 더 떨어지게 된다. Nagle 알고리즘은 확인응답이 올 때까지 데이터 전송을 지연시키고, 확인응답 지연 알고리즘은 확인응답을 100 ~ 200ms 정도 지연시키기 때문이다.
이 문제는 HTTP 스택이나 socket을 구현한 부분에 TCP_NODELAY 파라미터 값을 설정하여 Nagle 알고리즘을 비활성화 시키는 것으로 해결할 수 있다.
6. TIME_WAIT의 누적과 port 고갈
TCP 커넥션을 끊으면 각 endpoint 기기는 IP/포트를 메모리에 잠시 저장해 둔다. 이는 같은 주소와 포트를 사용하는 새로운 TCP 커넥션을 막기 위함이다. 이전 커넥션과 관련한 패킷이 새로 생성된 새 커넥션이 잘못 전송되는 것을 방지해 패킷 중복과 충돌을 막기 위한 조치이다. IP와 포트 정보는 보통 segment 최대 생명주기의 두 배정도 시간정도만 유지한다.
이는 일반적인 상황에서보다 성능측정을 하는 상황에서 문제가 생길 여지가 있다. 제한된 클라이언트와 제한된 서버로 성능측정을 하다보면 조합 가능한 IP와 포트의 숫자가 적어지기 때문이다. 결국 TIME_WAIT로 인하여 순간순간 포트를 재사용 하는 것이 불가능해 진다.
이는 생각보다 간단하게 해결가능 한데, 더 바로 더 많은 장비와 가상 IP를 사용하는 것이다 물론 간단하지 않을 수도 있다.
하나 더 기억할 부분은 포트 고갈 문제가 없더라도, 커넥션을 너무 많이 맺거나 대기상태의 제어 블록이 너무 많은 경우 OS에 따라 극심하게 성능이 떨어지기도 한다는 것이다.
3. HTTP의 성능에 대한 고려
1. 흔히 잘못 이해하는 Connection 헤더
HTTP는 클라이언트와 서버 사이에 proxy, cache 같은 중재자가 놓이는 것을 허락한다. 하지만 때로는 인접한 HTTP application끼리의 커넥션에만 적용될 옵션을 지정해야할 때가 있다. 예를들어 ‘클라이언트 - proxy - 서버’의 구조에서 ‘클라이언트 - proxy’간의 커넥션에만 적용되는 옵션을 설정해야하는 경우가 발생한다는 뜻이다.
HTTP의 Connection 헤더가 대표적으로서, 다음번 커넥션에는 영향을 끼치지 않고 현재 커넥션에만 영향을 줄 수 있는 옵션 설정이 가능하다.
Connection: meter, close, test
Meter: max-uses=3, max-refuse=6예를들어, 위와 같은 Connection 헤더가 있는 요청을 받았을 경우 다음과 같이 동작한다.
- 수신자는 송신자의 Connection 헤더에 있는 모든 요청을 적용한다.
- 다음 기기에는 Connection 헤더와 Connection 헤더에 기술된 Meter헤더를 삭제하여 message를 전달한다.
이를 hob-by-hob 헤더라고 한다. 이 헤더를 잘못사용하는 경우, 이를테면 뒤에서 살펴볼 dumb proxy가 클라이언트와 서버 사이에 있을 때 성능 문제를 야기할 수 있다.
2. 순차적 transaction에 의한 지연
예를 들어 3개의 이미지가 있는 웹페이지의 경우, HTML 파일과 3개의 이미지에 해당하는 총 네 번의 transaction을 생성해야한다.

Transaction 마다 새로운 커넥션이 만들어지고 끊어지면서 위에서 살펴본 3 way handshake 지연과 TCP slow start문제가 발생하게 된다.
이 문제는 다음 3가지 방법으로 해결할 수 있다.
- 병렬 커넥션
- 지속 커넥션
- 파이프라인 커넥션
이 방법에 대해서는 설명할 것이 조금 있기 때문에 다음 글에서 소개하고자 한다.
4. Conclusion
이 장은 내용이 조금 많으면서도 잘 모르고 있던 내용에 대해 알수 있게 되어서 좋았다. low level에서 동작하는 TCP의 동작에 대해서 조금이나마 알게 된 것이 대표적이다.
특히 내가 개발을 하거나 인터넷을 통한 활동을 할 때, 아무것도 모른 채 혜택을 받았던 많은 기능이 사실은 많은 사람들의 고민을 통해 적용된 것이라는 사실을 지금이라도 알게되어 다행이라고 생각했다.
요새 회사에서 개발하고 있는 서비스의 성능을 측정하고 개선하기 위해 준비하고 있는데 이번 장이 많은 도움이 될 것 같다.